|
I am a fifth-year PhD student at Boston University, advised by Prof. Eshed Ohn-Bar. Prior to BU, I worked with Dr. Dong Huang as a research assistant at the Human Sensing Lab. I got my master's degree (2016-2018) at the Robotics Institute of Carnegie Mellon University, where I worked with Prof. Kris Kitani, on pedestrian detection on low-profile robot. |

|
|
My research interests lie in computer vision, robotics and machine learning with their applications in autonomous and assistive systems. |
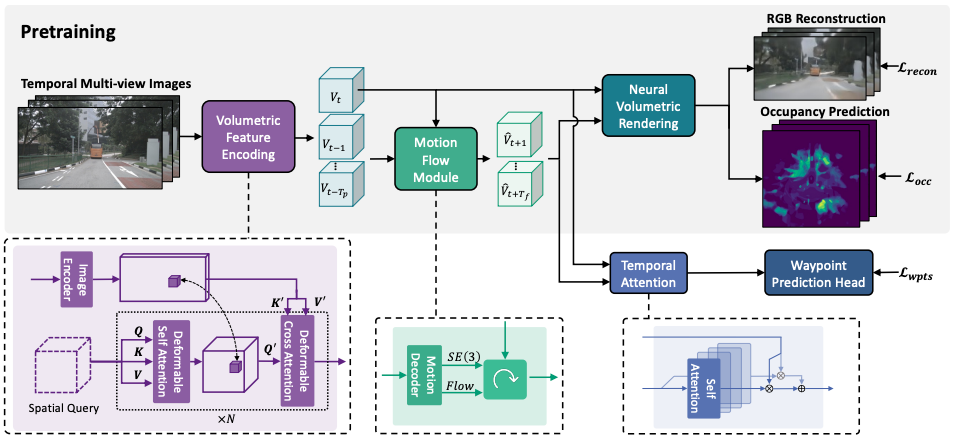 |
Jimuyang Zhang*, Zanming Huang*, Eshed Ohn-Bar European Conference on Computer Vision (ECCV), 2024 paper / webpage / video We introduce NeMo, a neural volumetric world modeling approach that can be trained in a self-supervised manner for image reconstruction and occupancy prediction tasks, benefiting scalable training and deployment paradigms such as imitation learning. We demonstrate how the higher-fidelity modeling of 3D volumetric representations benefits vision-based motion planning. We propose a motion flow module to model complex dynamic scenes, and introduce a temporal attention module to effectively integrate predicted future volumetric features for the planning task. |
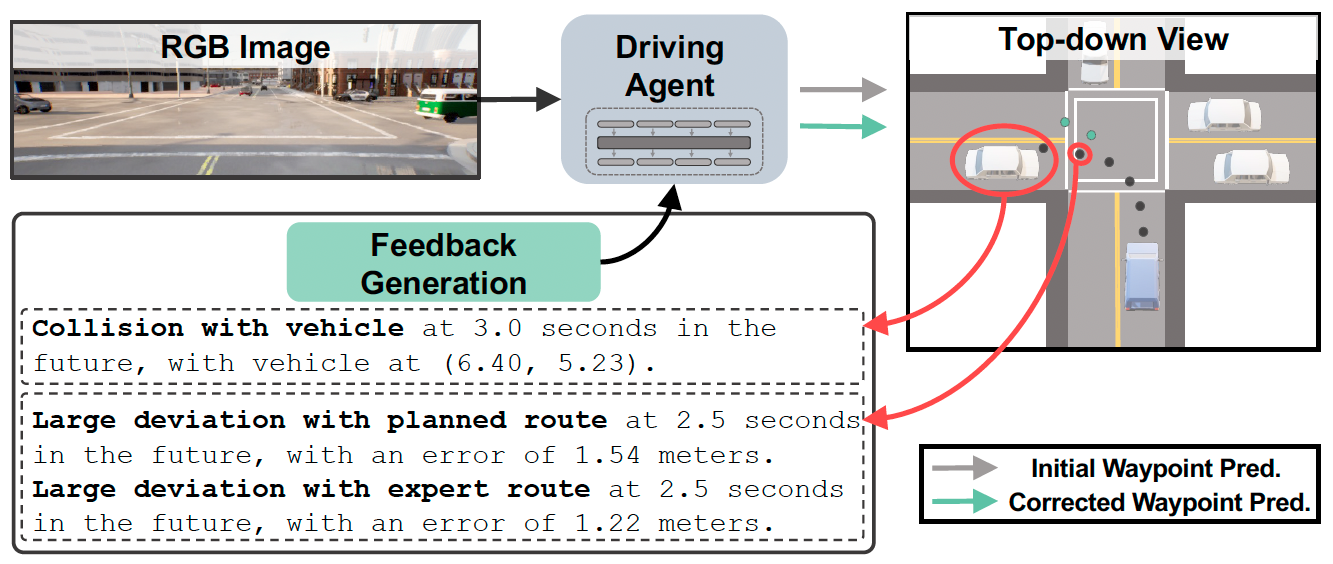 |
Jimuyang Zhang, Zanming Huang, Arijit Ray, Eshed Ohn-Bar Conference on Computer Vision and Pattern Recognition (CVPR), 2024 Highlight presentation (~top 2.8% of submitted papers) paper / webpage / video We introduce FeD, a highly efficient MLLM-based sensorimotor driving model, enabled by three key improvements: 1) language-based feedback refining trained using auto-generated feedback data. 2) training the model via distillation from a privileged agent with Bird's Eye View (BEV) of the scene, allowing our model to robustly use just RGB data at test time. 3) predicting driving waypoints in a masked-token fashion from the waypoint tokens' internal representations, i.e., not relying on the slow sequentially generative process. |
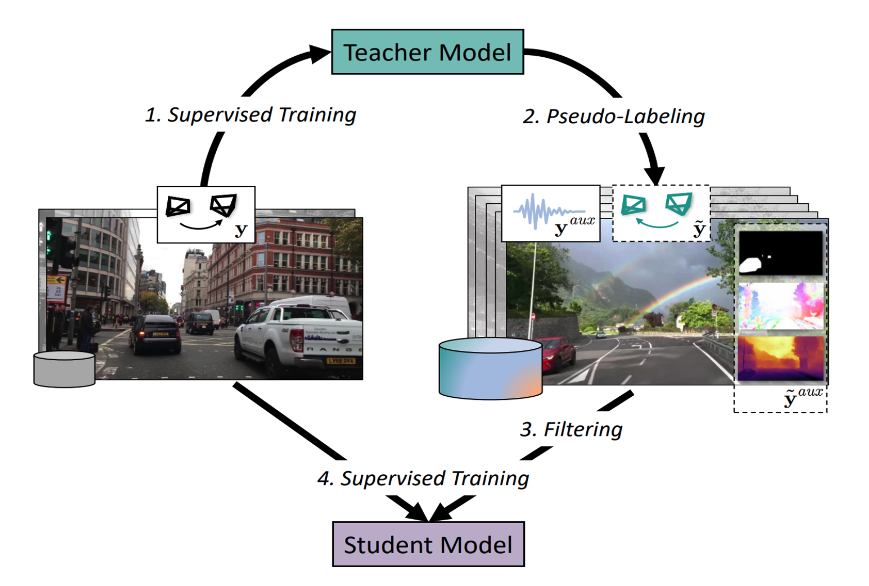 |
Lei Lai*, Zhongkai Shangguan*, Jimuyang Zhang, Eshed Ohn-Bar International Conference on Computer Vision (ICCV), 2023 paper / webpage We propose XVO, a semi-supervised learning method for training generalized monocular Visual Odometry (VO) models with robust off-the-shelf operation across diverse datasets and settings. We empirically demonstrate the benefits of semi-supervised training for learning a general-purpose direct VO regression network. Moreover, we demonstrate multi-modal supervision, including segmentation, flow, depth, and audio auxiliary prediction tasks, to facilitate generalized representations for the VO task. |
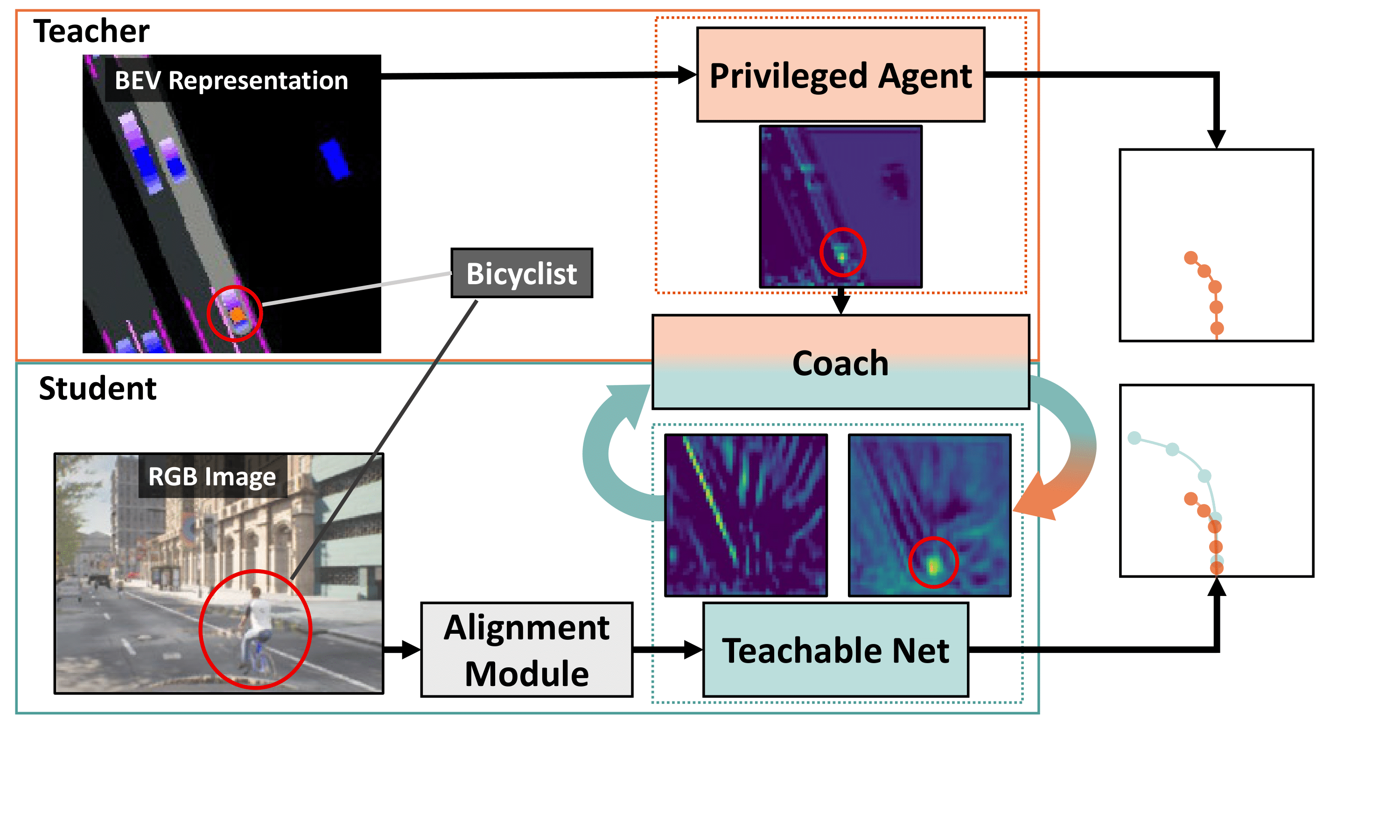 |
Jimuyang Zhang, Zanming Huang, Eshed Ohn-Bar Conference on Computer Vision and Pattern Recognition (CVPR), 2023 Highlight presentation (~top 2.5% of submitted papers) paper / webpage We propose a novel knowledge distillation framework for effectively teaching a sensorimotor student agent to drive from the supervision of a privileged teacher agent. Our proposed sensorimotor agent results in a robust image-based behavior cloning agent in CARLA, improving over current models by over 20.6% in driving score without requiring LiDAR, historical observations, ensemble of models, on-policy data aggregation or reinforcement learning. |
 |
Zanming Huang*, Zhongkai Shangguan*, Jimuyang Zhang, Gilad Bar, Matthew Boyd, Eshed Ohn-Bar European Conference on Computer Vision (ECCV), 2022 paper / data and code We introduce a novel vision-and-language navigation (VLN) task of learning to provide real-time guidance to a blind follower situated in complex dynamic navigation scenarios. We collect a multi-modal real-world benchmark with in-situ Orientation and Mobility (O&M) instructional guidance. We leverage the real-world study to inform the design of a larger-scale simulation benchmark. In the end, we present ASSISTER, an imitation-learned agent that can embody such effective guidance. |
 |
Jimuyang Zhang, Ruizhao Zhu, Eshed Ohn-Bar Conference on Computer Vision and Pattern Recognition (CVPR), 2022 arxiv / video We introduce SelfD, a framework for learning scalable driving by utilizing large amounts of online monocular images. Our key idea is to leverage iterative semi-supervised training when learning imitative agents from unlabeled data. We employ a large dataset of publicly available YouTube videos to train SelfD and comprehensively analyze its generalization benefits across challenging navigation scenarios. SelfD demonstrates consistent improvements (by up to 24%) in driving performance evaluation on nuScenes, Argoverse, Waymo, and CARLA. |
 |
Jimuyang Zhang*, Minglan Zheng*, Matthew Boyd, Eshed Ohn-Bar International Conference on Computer Vision (ICCV), 2021 arxiv / video / talk / workshop / challenge We introduce X-World, an accessibility-centered development environment for vision-based autonomous systems, which enables spawning dynamic agents with various mobility aids. The simulation supports generation of ample amounts of finely annotated, multi-modal data in a safe, cheap, and privacy-preserving manner. We highlight novel difficulties introduced by our benchmark and tasks, as well as opportunities for future developments. We further validate and extend our analysis by introducing a complementary real-world evaluation benchmark. |
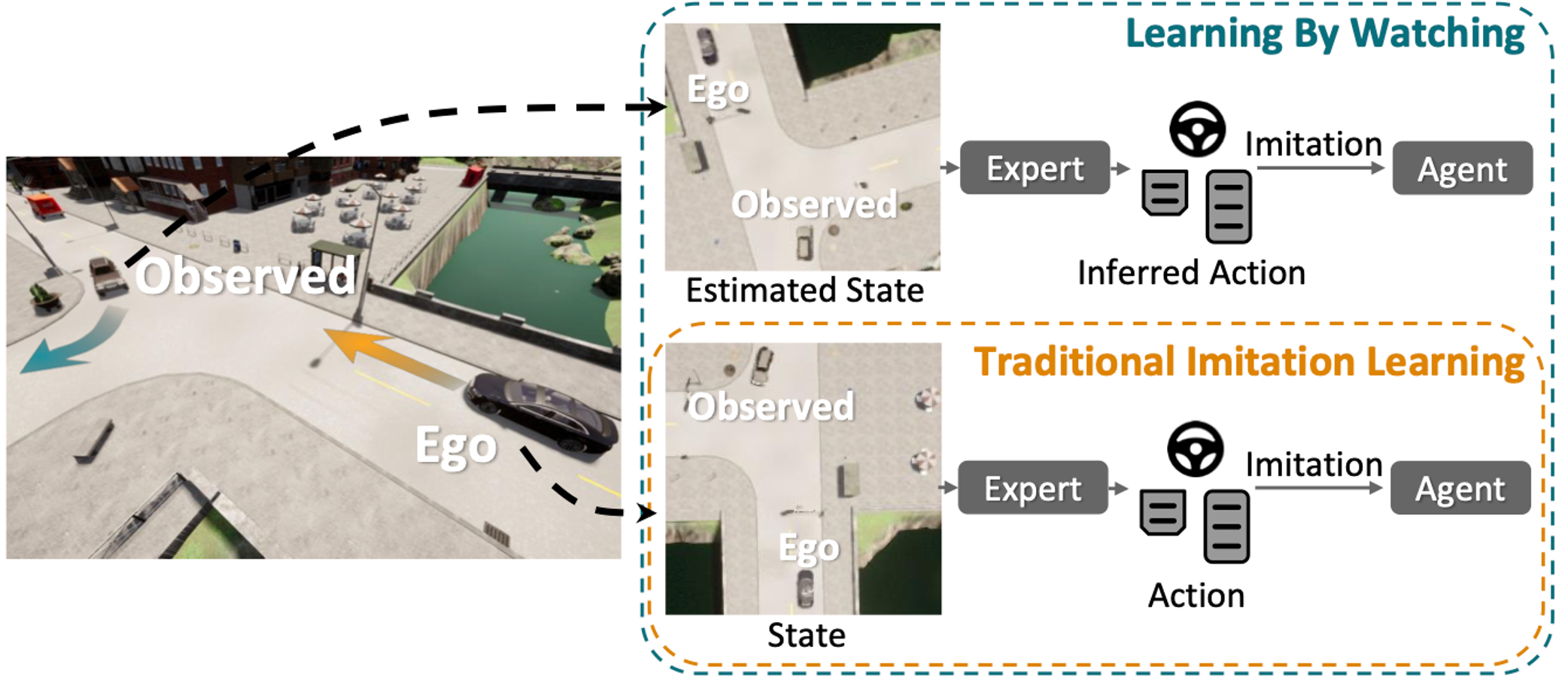 |
Jimuyang Zhang, Eshed Ohn-Bar Conference on Computer Vision and Pattern Recognition (CVPR), 2021 arxiv / video We propose the Learning by Watching (LbW) framework which enables learning a driving policy without requiring full knowledge of neither the state nor expert actions. To increase its data, i.e., with new perspectives and maneuvers, LbW makes use of the demonstrations of other vehicles in a given scene by (1) transforming the egovehicle’s observations to their points of view, and (2) inferring their expert actions. Our LbW agent learns more robust driving policies while enabling data-efficient learning, including quick adaptation of the policy to rare and novel scenarios. |
|
Jimuyang Zhang, Sanping Zhou, Xin Chang, Fangbin Wan, Jinjun Wang, Yang Wu, Dong Huang arXiv, 2020 arxiv We design an end-to-end DNN tracking approach, Flow-Fuse-Tracker (FFT), consisting of two efficient techniques: target flowing and target fusing. In target flowing, a FlowTracker DNN module learns the indefinite number of target-wise motions jointly from pixel-level optical flows. In target fusing, a FuseTracker DNN module refines and fuses targets proposed by FlowTracker and frame-wise object detection, instead of trusting either of the two inaccurate sources of target proposal. |
|
ENG EC 500 - Robot Learning and Vision for Navigation - Spring 2023
ENG EC 444 - Smart and Connected Systems - Fall 2022
ENG EC 503 - Introduction to Learning from Data - Fall 2021
|
|
CVPR2022 AVA Accessibility Vision and Autonomy Challenge
|
This website was forked from source code